(換膚)
語(yǔ)言:

文章編號(hào):11498時(shí)間:2024-10-01人氣:
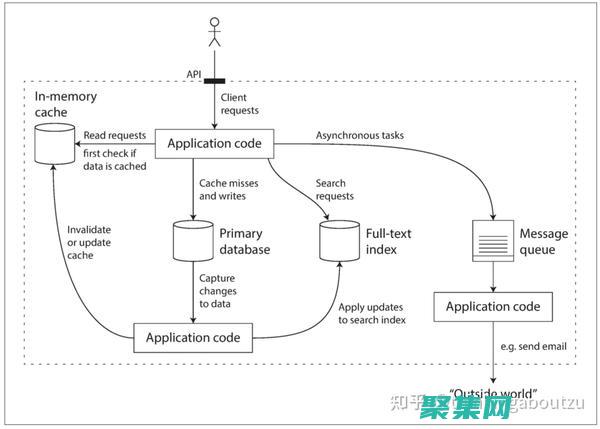
HDFS運(yùn)行流程:客戶端通過(guò)調(diào)用FileSystem的open方法獲取需要讀取的數(shù)據(jù)文件。

HDFS通過(guò)RPC來(lái)調(diào)用NameNode,獲取要讀取的數(shù)據(jù)文件對(duì)應(yīng)的block存放在哪些DataNode上。 客戶端先到距離最近的DataNode上調(diào)用FSDataInputStream的read方法,將數(shù)據(jù)從DataNode傳輸?shù)娇蛻舳恕?
當(dāng)讀取完所有的數(shù)據(jù)后,F(xiàn)SDataInputstream會(huì)關(guān)閉與DataNode的連接,尋找下一塊的最佳位置(即距離最近的下一塊)。 當(dāng)客戶端完成讀取操作之后,會(huì)調(diào)用FSDataInputStream的close方法完成對(duì)資源的關(guān)閉工作。 這個(gè)流程確保了數(shù)據(jù)的可靠存儲(chǔ)和高效訪問(wèn),滿足了大規(guī)模數(shù)據(jù)處理的需求。
HDFS的優(yōu)勢(shì)
1、高容錯(cuò)性:HDFS采用了數(shù)據(jù)塊的副本機(jī)制,當(dāng)某個(gè)數(shù)據(jù)塊丟失或損壞時(shí),可以從其他副本中恢復(fù),確保了數(shù)據(jù)的可靠性和可用性。
2、可擴(kuò)展性:HDFS可以在普通的硬件上運(yùn)行,并且可以通過(guò)增加節(jié)點(diǎn)來(lái)擴(kuò)展存儲(chǔ)和計(jì)算能力,滿足了大規(guī)模數(shù)據(jù)處理的需求。
3、簡(jiǎn)單一致性模型:HDFS采用了“一次寫入,多次讀取”的模式,數(shù)據(jù)一旦寫入,就被永久存儲(chǔ),并且可以隨時(shí)讀取,保證了數(shù)據(jù)的一致性。
4、支持大規(guī)模數(shù)據(jù):由于數(shù)據(jù)被分散存儲(chǔ)在多個(gè)節(jié)點(diǎn)上,HDFS可以處理GB、TB甚至PB級(jí)別的數(shù)據(jù),適合存儲(chǔ)和分析大規(guī)模數(shù)據(jù)集。
5、支持多種文件類型:除了常規(guī)的文件,HDFS還支持圖片、視頻、音頻等多種文件類型,可以滿足各種應(yīng)用的需求。
學(xué)習(xí)大數(shù)據(jù)肯定需要學(xué)習(xí)Hadoop技術(shù),Hadoop在大數(shù)據(jù)技術(shù)體系中的地位至關(guān)重要,Hadoop是大數(shù)據(jù)技術(shù)的基礎(chǔ),對(duì)Hadoop基礎(chǔ)知識(shí)的掌握的扎實(shí)程度,會(huì)決定在大數(shù)據(jù)技術(shù)道路上走多遠(yuǎn)。
Hadoop學(xué)習(xí)之后,還得學(xué)習(xí)Spark,它是一種與 Hadoop 相似的開源集群計(jì)算環(huán)境,擁有Hadoop MapReduce所具有的優(yōu)點(diǎn),Spark是MapReduce的替代方案,而且兼容HDFS、Hive,可融入Hadoop的生態(tài)系統(tǒng),以彌補(bǔ)MapReduce的不足。
這是大數(shù)據(jù)技術(shù)學(xué)習(xí)的兩大重點(diǎn)。
HDFS(Hadoop Distributed File System)不被歸類為NoSQL數(shù)據(jù)庫(kù),因?yàn)樗欠植际轿募到y(tǒng)而不是數(shù)據(jù)庫(kù)。 HDFS是Apache Hadoop生態(tài)系統(tǒng)的一部分,旨在存儲(chǔ)和處理大規(guī)模數(shù)據(jù)集。 盡管HDFS非常適合用于存儲(chǔ)和處理大規(guī)模的結(jié)構(gòu)化和非結(jié)構(gòu)化數(shù)據(jù),但作為數(shù)據(jù)庫(kù),它存在以下一些不足之處:1. 缺乏事務(wù)支持:HDFS不支持事務(wù),這意味著無(wú)法保證數(shù)據(jù)的一致性和完整性。 如果需要強(qiáng)一致性和事務(wù)支持的數(shù)據(jù)庫(kù)操作,HDFS并不是一個(gè)理想的選擇。 2. 有限的查詢能力:HDFS的設(shè)計(jì)目的是高吞吐量的批量處理,而不是實(shí)時(shí)交互式查詢。 雖然Hadoop生態(tài)系統(tǒng)提供了一些查詢工具(如Hive、Pig等),但相對(duì)于傳統(tǒng)的關(guān)系型數(shù)據(jù)庫(kù),HDFS的查詢能力仍然有限。 3. 無(wú)結(jié)構(gòu)化數(shù)據(jù)管理:HDFS主要用于存儲(chǔ)和處理大規(guī)模的非結(jié)構(gòu)化數(shù)據(jù)(如日志文件、圖像、視頻等),而對(duì)于結(jié)構(gòu)化數(shù)據(jù)的管理相對(duì)較弱。 與傳統(tǒng)的關(guān)系型數(shù)據(jù)庫(kù)相比,HDFS缺乏對(duì)表關(guān)系、查詢優(yōu)化和數(shù)據(jù)約束的內(nèi)建支持。 4. 難以更新和刪除數(shù)據(jù):HDFS的設(shè)計(jì)重點(diǎn)是數(shù)據(jù)追加和批量處理,而不是頻繁的數(shù)據(jù)更新和刪除。 在HDFS上更新和刪除數(shù)據(jù)可能需要執(zhí)行較為復(fù)雜的操作,且性能可能受到影響。 5. 數(shù)據(jù)一致性的挑戰(zhàn):由于HDFS是分布式的,數(shù)據(jù)的一致性可能面臨挑戰(zhàn)。 在復(fù)制模式下,HDFS會(huì)將數(shù)據(jù)復(fù)制到多個(gè)節(jié)點(diǎn)上,但由于數(shù)據(jù)復(fù)制的異步性質(zhì),數(shù)據(jù)的讀取一致性可能受到影響。 綜上所述,盡管HDFS具有存儲(chǔ)和處理大規(guī)模數(shù)據(jù)的優(yōu)勢(shì),但作為數(shù)據(jù)庫(kù),它仍然存在一些不足之處。 對(duì)于需要事務(wù)支持、強(qiáng)一致性和復(fù)雜查詢操作的應(yīng)用場(chǎng)景,傳統(tǒng)的關(guān)系型數(shù)據(jù)庫(kù)或NoSQL數(shù)據(jù)庫(kù)可能更為適合。
五種大數(shù)據(jù)處理架構(gòu)大數(shù)據(jù)是收集、整理、處理大容量數(shù)據(jù)集,并從中獲得見(jiàn)解所需的非傳統(tǒng)戰(zhàn)略和技術(shù)的總稱。 雖然處理數(shù)據(jù)所需的計(jì)算能力或存儲(chǔ)容量早已超過(guò)一臺(tái)計(jì)算機(jī)的上限,但這種計(jì)算類型的普遍性、規(guī)模,以及價(jià)值在最近幾年才經(jīng)歷了大規(guī)模擴(kuò)展。 本文將介紹大數(shù)據(jù)系統(tǒng)一個(gè)最基本的組件:處理框架。 處理框架負(fù)責(zé)對(duì)系統(tǒng)中的數(shù)據(jù)進(jìn)行計(jì)算,例如處理從非易失存儲(chǔ)中讀取的數(shù)據(jù),或處理剛剛攝入到系統(tǒng)中的數(shù)據(jù)。 數(shù)據(jù)的計(jì)算則是指從大量單一數(shù)據(jù)點(diǎn)中提取信息和見(jiàn)解的過(guò)程。 下文將介紹這些框架:· 僅批處理框架:Apache Hadoop· 僅流處理框架:Apache StormApache Samza· 混合框架:Apache SparkApache Flink大數(shù)據(jù)處理框架是什么?處理框架和處理引擎負(fù)責(zé)對(duì)數(shù)據(jù)系統(tǒng)中的數(shù)據(jù)進(jìn)行計(jì)算。 雖然“引擎”和“框架”之間的區(qū)別沒(méi)有什么權(quán)威的定義,但大部分時(shí)候可以將前者定義為實(shí)際負(fù)責(zé)處理數(shù)據(jù)操作的組件,后者則可定義為承擔(dān)類似作用的一系列組件。 例如Apache Hadoop可以看作一種以MapReduce作為默認(rèn)處理引擎的處理框架。 引擎和框架通常可以相互替換或同時(shí)使用。 例如另一個(gè)框架Apache Spark可以納入Hadoop并取代MapReduce。 組件之間的這種互操作性是大數(shù)據(jù)系統(tǒng)靈活性如此之高的原因之一。 雖然負(fù)責(zé)處理生命周期內(nèi)這一階段數(shù)據(jù)的系統(tǒng)通常都很復(fù)雜,但從廣義層面來(lái)看它們的目標(biāo)是非常一致的:通過(guò)對(duì)數(shù)據(jù)執(zhí)行操作提高理解能力,揭示出數(shù)據(jù)蘊(yùn)含的模式,并針對(duì)復(fù)雜互動(dòng)獲得見(jiàn)解。 為了簡(jiǎn)化這些組件的討論,我們會(huì)通過(guò)不同處理框架的設(shè)計(jì)意圖,按照所處理的數(shù)據(jù)狀態(tài)對(duì)其進(jìn)行分類。 一些系統(tǒng)可以用批處理方式處理數(shù)據(jù),一些系統(tǒng)可以用流方式處理連續(xù)不斷流入系統(tǒng)的數(shù)據(jù)。 此外還有一些系統(tǒng)可以同時(shí)處理這兩類數(shù)據(jù)。 在深入介紹不同實(shí)現(xiàn)的指標(biāo)和結(jié)論之前,首先需要對(duì)不同處理類型的概念進(jìn)行一個(gè)簡(jiǎn)單的介紹。 批處理系統(tǒng)批處理在大數(shù)據(jù)世界有著悠久的歷史。 批處理主要操作大容量靜態(tài)數(shù)據(jù)集,并在計(jì)算過(guò)程完成后返回結(jié)果。 批處理模式中使用的數(shù)據(jù)集通常符合下列特征…· 有界:批處理數(shù)據(jù)集代表數(shù)據(jù)的有限集合· 持久:數(shù)據(jù)通常始終存儲(chǔ)在某種類型的持久存儲(chǔ)位置中· 大量:批處理操作通常是處理極為海量數(shù)據(jù)集的唯一方法批處理非常適合需要訪問(wèn)全套記錄才能完成的計(jì)算工作。 例如在計(jì)算總數(shù)和平均數(shù)時(shí),必須將數(shù)據(jù)集作為一個(gè)整體加以處理,而不能將其視作多條記錄的集合。 這些操作要求在計(jì)算進(jìn)行過(guò)程中數(shù)據(jù)維持自己的狀態(tài)。 需要處理大量數(shù)據(jù)的任務(wù)通常最適合用批處理操作進(jìn)行處理。 無(wú)論直接從持久存儲(chǔ)設(shè)備處理數(shù)據(jù)集,或首先將數(shù)據(jù)集載入內(nèi)存,批處理系統(tǒng)在設(shè)計(jì)過(guò)程中就充分考慮了數(shù)據(jù)的量,可提供充足的處理資源。 由于批處理在應(yīng)對(duì)大量持久數(shù)據(jù)方面的表現(xiàn)極為出色,因此經(jīng)常被用于對(duì)歷史數(shù)據(jù)進(jìn)行分析。 大量數(shù)據(jù)的處理需要付出大量時(shí)間,因此批處理不適合對(duì)處理時(shí)間要求較高的場(chǎng)合。 Apache HadoopApache Hadoop是一種專用于批處理的處理框架。 Hadoop是首個(gè)在開源社區(qū)獲得極大關(guān)注的大數(shù)據(jù)框架。 基于谷歌有關(guān)海量數(shù)據(jù)處理所發(fā)表的多篇論文與經(jīng)驗(yàn)的Hadoop重新實(shí)現(xiàn)了相關(guān)算法和組件堆棧,讓大規(guī)模批處理技術(shù)變得更易用。 新版Hadoop包含多個(gè)組件,即多個(gè)層,通過(guò)配合使用可處理批數(shù)據(jù):· HDFS:HDFS是一種分布式文件系統(tǒng)層,可對(duì)集群節(jié)點(diǎn)間的存儲(chǔ)和復(fù)制進(jìn)行協(xié)調(diào)。 HDFS確保了無(wú)法避免的節(jié)點(diǎn)故障發(fā)生后數(shù)據(jù)依然可用,可將其用作數(shù)據(jù)來(lái)源,可用于存儲(chǔ)中間態(tài)的處理結(jié)果,并可存儲(chǔ)計(jì)算的最終結(jié)果。 · YARN:YARN是Yet Another Resource Negotiator(另一個(gè)資源管理器)的縮寫,可充當(dāng)Hadoop堆棧的集群協(xié)調(diào)組件。 該組件負(fù)責(zé)協(xié)調(diào)并管理底層資源和調(diào)度作業(yè)的運(yùn)行。 通過(guò)充當(dāng)集群資源的接口,YARN使得用戶能在Hadoop集群中使用比以往的迭代方式運(yùn)行更多類型的工作負(fù)載。 · MapReduce:MapReduce是Hadoop的原生批處理引擎。 批處理模式Hadoop的處理功能來(lái)自MapReduce引擎。 MapReduce的處理技術(shù)符合使用鍵值對(duì)的map、shuffle、reduce算法要求。 基本處理過(guò)程包括:· 從HDFS文件系統(tǒng)讀取數(shù)據(jù)集· 將數(shù)據(jù)集拆分成小塊并分配給所有可用節(jié)點(diǎn)· 針對(duì)每個(gè)節(jié)點(diǎn)上的數(shù)據(jù)子集進(jìn)行計(jì)算(計(jì)算的中間態(tài)結(jié)果會(huì)重新寫入HDFS)· 重新分配中間態(tài)結(jié)果并按照鍵進(jìn)行分組· 通過(guò)對(duì)每個(gè)節(jié)點(diǎn)計(jì)算的結(jié)果進(jìn)行匯總和組合對(duì)每個(gè)鍵的值進(jìn)行“Reducing”· 將計(jì)算而來(lái)的最終結(jié)果重新寫入 HDFS優(yōu)勢(shì)和局限由于這種方法嚴(yán)重依賴持久存儲(chǔ),每個(gè)任務(wù)需要多次執(zhí)行讀取和寫入操作,因此速度相對(duì)較慢。 但另一方面由于磁盤空間通常是服務(wù)器上最豐富的資源,這意味著MapReduce可以處理非常海量的數(shù)據(jù)集。 同時(shí)也意味著相比其他類似技術(shù),Hadoop的MapReduce通常可以在廉價(jià)硬件上運(yùn)行,因?yàn)樵摷夹g(shù)并不需要將一切都存儲(chǔ)在內(nèi)存中。 MapReduce具備極高的縮放潛力,生產(chǎn)環(huán)境中曾經(jīng)出現(xiàn)過(guò)包含數(shù)萬(wàn)個(gè)節(jié)點(diǎn)的應(yīng)用。 MapReduce的學(xué)習(xí)曲線較為陡峭,雖然Hadoop生態(tài)系統(tǒng)的其他周邊技術(shù)可以大幅降低這一問(wèn)題的影響,但通過(guò)Hadoop集群快速實(shí)現(xiàn)某些應(yīng)用時(shí)依然需要注意這個(gè)問(wèn)題。 圍繞Hadoop已經(jīng)形成了遼闊的生態(tài)系統(tǒng),Hadoop集群本身也經(jīng)常被用作其他軟件的組成部件。 很多其他處理框架和引擎通過(guò)與Hadoop集成也可以使用HDFS和YARN資源管理器。 總結(jié)Apache Hadoop及其MapReduce處理引擎提供了一套久經(jīng)考驗(yàn)的批處理模型,最適合處理對(duì)時(shí)間要求不高的非常大規(guī)模數(shù)據(jù)集。 通過(guò)非常低成本的組件即可搭建完整功能的Hadoop集群,使得這一廉價(jià)且高效的處理技術(shù)可以靈活應(yīng)用在很多案例中。 與其他框架和引擎的兼容與集成能力使得Hadoop可以成為使用不同技術(shù)的多種工作負(fù)載處理平臺(tái)的底層基礎(chǔ)。 流處理系統(tǒng)流處理系統(tǒng)會(huì)對(duì)隨時(shí)進(jìn)入系統(tǒng)的數(shù)據(jù)進(jìn)行計(jì)算。 相比批處理模式,這是一種截然不同的處理方式。 流處理方式無(wú)需針對(duì)整個(gè)數(shù)據(jù)集執(zhí)行操作,而是對(duì)通過(guò)系統(tǒng)傳輸?shù)拿總€(gè)數(shù)據(jù)項(xiàng)執(zhí)行操作。 · 流處理中的數(shù)據(jù)集是“無(wú)邊界”的,這就產(chǎn)生了幾個(gè)重要的影響:· 完整數(shù)據(jù)集只能代表截至目前已經(jīng)進(jìn)入到系統(tǒng)中的數(shù)據(jù)總量。 · 工作數(shù)據(jù)集也許更相關(guān),在特定時(shí)間只能代表某個(gè)單一數(shù)據(jù)項(xiàng)。 處理工作是基于事件的,除非明確停止否則沒(méi)有“盡頭”。 處理結(jié)果立刻可用,并會(huì)隨著新數(shù)據(jù)的抵達(dá)繼續(xù)更新。 流處理系統(tǒng)可以處理幾乎無(wú)限量的數(shù)據(jù),但同一時(shí)間只能處理一條(真正的流處理)或很少量(微批處理,Micro-batch Processing)數(shù)據(jù),不同記錄間只維持最少量的狀態(tài)。 雖然大部分系統(tǒng)提供了用于維持某些狀態(tài)的方法,但流處理主要針對(duì)副作用更少,更加功能性的處理(Functional processing)進(jìn)行優(yōu)化。 功能性操作主要側(cè)重于狀態(tài)或副作用有限的離散步驟。 針對(duì)同一個(gè)數(shù)據(jù)執(zhí)行同一個(gè)操作會(huì)或略其他因素產(chǎn)生相同的結(jié)果,此類處理非常適合流處理,因?yàn)椴煌?xiàng)的狀態(tài)通常是某些困難、限制,以及某些情況下不需要的結(jié)果的結(jié)合體。 因此雖然某些類型的狀態(tài)管理通常是可行的,但這些框架通常在不具備狀態(tài)管理機(jī)制時(shí)更簡(jiǎn)單也更高效。 此類處理非常適合某些類型的工作負(fù)載。 有近實(shí)時(shí)處理需求的任務(wù)很適合使用流處理模式。 分析、服務(wù)器或應(yīng)用程序錯(cuò)誤日志,以及其他基于時(shí)間的衡量指標(biāo)是最適合的類型,因?yàn)閷?duì)這些領(lǐng)域的數(shù)據(jù)變化做出響應(yīng)對(duì)于業(yè)務(wù)職能來(lái)說(shuō)是極為關(guān)鍵的。 流處理很適合用來(lái)處理必須對(duì)變動(dòng)或峰值做出響應(yīng),并且關(guān)注一段時(shí)間內(nèi)變化趨勢(shì)的數(shù)據(jù)。 Apache StormApache Storm是一種側(cè)重于極低延遲的流處理框架,也許是要求近實(shí)時(shí)處理的工作負(fù)載的最佳選擇。 該技術(shù)可處理非常大量的數(shù)據(jù),通過(guò)比其他解決方案更低的延遲提供結(jié)果。 流處理模式Storm的流處理可對(duì)框架中名為Topology(拓?fù)洌┑腄AG(Directed Acyclic Graph,有向無(wú)環(huán)圖)進(jìn)行編排。 這些拓?fù)涿枋隽水?dāng)數(shù)據(jù)片段進(jìn)入系統(tǒng)后,需要對(duì)每個(gè)傳入的片段執(zhí)行的不同轉(zhuǎn)換或步驟。 拓?fù)浒骸?Stream:普通的數(shù)據(jù)流,這是一種會(huì)持續(xù)抵達(dá)系統(tǒng)的無(wú)邊界數(shù)據(jù)。 · Spout:位于拓?fù)溥吘壍臄?shù)據(jù)流來(lái)源,例如可以是API或查詢等,從這里可以產(chǎn)生待處理的數(shù)據(jù)。 · Bolt:Bolt代表需要消耗流數(shù)據(jù),對(duì)其應(yīng)用操作,并將結(jié)果以流的形式進(jìn)行輸出的處理步驟。 Bolt需要與每個(gè)Spout建立連接,隨后相互連接以組成所有必要的處理。 在拓?fù)涞奈膊浚梢允褂米罱K的Bolt輸出作為相互連接的其他系統(tǒng)的輸入。 Storm背后的想法是使用上述組件定義大量小型的離散操作,隨后將多個(gè)組件組成所需拓?fù)洹? 默認(rèn)情況下Storm提供了“至少一次”的處理保證,這意味著可以確保每條消息至少可以被處理一次,但某些情況下如果遇到失敗可能會(huì)處理多次。 Storm無(wú)法確保可以按照特定順序處理消息。 為了實(shí)現(xiàn)嚴(yán)格的一次處理,即有狀態(tài)處理,可以使用一種名為Trident的抽象。 嚴(yán)格來(lái)說(shuō)不使用Trident的Storm通常可稱之為Core Storm。 Trident會(huì)對(duì)Storm的處理能力產(chǎn)生極大影響,會(huì)增加延遲,為處理提供狀態(tài),使用微批模式代替逐項(xiàng)處理的純粹流處理模式。 為避免這些問(wèn)題,通常建議Storm用戶盡可能使用Core Storm。 然而也要注意,Trident對(duì)內(nèi)容嚴(yán)格的一次處理保證在某些情況下也比較有用,例如系統(tǒng)無(wú)法智能地處理重復(fù)消息時(shí)。 如果需要在項(xiàng)之間維持狀態(tài),例如想要計(jì)算一個(gè)小時(shí)內(nèi)有多少用戶點(diǎn)擊了某個(gè)鏈接,此時(shí)Trident將是你唯一的選擇。 盡管不能充分發(fā)揮框架與生俱來(lái)的優(yōu)勢(shì),但Trident提高了Storm的靈活性。 Trident拓?fù)浒骸?流批(Stream batch):這是指流數(shù)據(jù)的微批,可通過(guò)分塊提供批處理語(yǔ)義。 · 操作(Operation):是指可以對(duì)數(shù)據(jù)執(zhí)行的批處理過(guò)程。 優(yōu)勢(shì)和局限目前來(lái)說(shuō)Storm可能是近實(shí)時(shí)處理領(lǐng)域的最佳解決方案。 該技術(shù)可以用極低延遲處理數(shù)據(jù),可用于希望獲得最低延遲的工作負(fù)載。 如果處理速度直接影響用戶體驗(yàn),例如需要將處理結(jié)果直接提供給訪客打開的網(wǎng)站頁(yè)面,此時(shí)Storm將會(huì)是一個(gè)很好的選擇。 Storm與Trident配合使得用戶可以用微批代替純粹的流處理。 雖然借此用戶可以獲得更大靈活性打造更符合要求的工具,但同時(shí)這種做法會(huì)削弱該技術(shù)相比其他解決方案最大的優(yōu)勢(shì)。 話雖如此,但多一種流處理方式總是好的。 Core Storm無(wú)法保證消息的處理順序。 Core Storm為消息提供了“至少一次”的處理保證,這意味著可以保證每條消息都能被處理,但也可能發(fā)生重復(fù)。 Trident提供了嚴(yán)格的一次處理保證,可以在不同批之間提供順序處理,但無(wú)法在一個(gè)批內(nèi)部實(shí)現(xiàn)順序處理。 在互操作性方面,Storm可與Hadoop的YARN資源管理器進(jìn)行集成,因此可以很方便地融入現(xiàn)有Hadoop部署。 除了支持大部分處理框架,Storm還可支持多種語(yǔ)言,為用戶的拓?fù)涠x提供了更多選擇。 總結(jié)對(duì)于延遲需求很高的純粹的流處理工作負(fù)載,Storm可能是最適合的技術(shù)。 該技術(shù)可以保證每條消息都被處理,可配合多種編程語(yǔ)言使用。 由于Storm無(wú)法進(jìn)行批處理,如果需要這些能力可能還需要使用其他軟件。 如果對(duì)嚴(yán)格的一次處理保證有比較高的要求,此時(shí)可考慮使用Trident。 不過(guò)這種情況下其他流處理框架也許更適合。 Apache SamzaApache Samza是一種與Apache Kafka消息系統(tǒng)緊密綁定的流處理框架。 雖然Kafka可用于很多流處理系統(tǒng),但按照設(shè)計(jì),Samza可以更好地發(fā)揮Kafka獨(dú)特的架構(gòu)優(yōu)勢(shì)和保障。 該技術(shù)可通過(guò)Kafka提供容錯(cuò)、緩沖,以及狀態(tài)存儲(chǔ)。 Samza可使用YARN作為資源管理器。 這意味著默認(rèn)情況下需要具備Hadoop集群(至少具備HDFS和YARN),但同時(shí)也意味著Samza可以直接使用YARN豐富的內(nèi)建功能。 流處理模式Samza依賴Kafka的語(yǔ)義定義流的處理方式。 Kafka在處理數(shù)據(jù)時(shí)涉及下列概念:· Topic(話題):進(jìn)入Kafka系統(tǒng)的每個(gè)數(shù)據(jù)流可稱之為一個(gè)話題。 話題基本上是一種可供消耗方訂閱的,由相關(guān)信息組成的數(shù)據(jù)流。 · Partition(分區(qū)):為了將一個(gè)話題分散至多個(gè)節(jié)點(diǎn),Kafka會(huì)將傳入的消息劃分為多個(gè)分區(qū)。 分區(qū)的劃分將基于鍵(Key)進(jìn)行,這樣可以保證包含同一個(gè)鍵的每條消息可以劃分至同一個(gè)分區(qū)。 分區(qū)的順序可獲得保證。 · Broker(代理):組成Kafka集群的每個(gè)節(jié)點(diǎn)也叫做代理。 · Producer(生成方):任何向Kafka話題寫入數(shù)據(jù)的組件可以叫做生成方。 生成方可提供將話題劃分為分區(qū)所需的鍵。 · Consumer(消耗方):任何從Kafka讀取話題的組件可叫做消耗方。 消耗方需要負(fù)責(zé)維持有關(guān)自己分支的信息,這樣即可在失敗后知道哪些記錄已經(jīng)被處理過(guò)了。 由于Kafka相當(dāng)于永恒不變的日志,Samza也需要處理永恒不變的數(shù)據(jù)流。 這意味著任何轉(zhuǎn)換創(chuàng)建的新數(shù)據(jù)流都可被其他組件所使用,而不會(huì)對(duì)最初的數(shù)據(jù)流產(chǎn)生影響。 優(yōu)勢(shì)和局限乍看之下,Samza對(duì)Kafka類查詢系統(tǒng)的依賴似乎是一種限制,然而這也可以為系統(tǒng)提供一些獨(dú)特的保證和功能,這些內(nèi)容也是其他流處理系統(tǒng)不具備的。 例如Kafka已經(jīng)提供了可以通過(guò)低延遲方式訪問(wèn)的數(shù)據(jù)存儲(chǔ)副本,此外還可以為每個(gè)數(shù)據(jù)分區(qū)提供非常易用且低成本的多訂閱者模型。 所有輸出內(nèi)容,包括中間態(tài)的結(jié)果都可寫入到Kafka,并可被下游步驟獨(dú)立使用。 這種對(duì)Kafka的緊密依賴在很多方面類似于MapReduce引擎對(duì)HDFS的依賴。 雖然在批處理的每個(gè)計(jì)算之間對(duì)HDFS的依賴導(dǎo)致了一些嚴(yán)重的性能問(wèn)題,但也避免了流處理遇到的很多其他問(wèn)題。 Samza與Kafka之間緊密的關(guān)系使得處理步驟本身可以非常松散地耦合在一起。 無(wú)需事先協(xié)調(diào),即可在輸出的任何步驟中增加任意數(shù)量的訂閱者,對(duì)于有多個(gè)團(tuán)隊(duì)需要訪問(wèn)類似數(shù)據(jù)的組織,這一特性非常有用。 多個(gè)團(tuán)隊(duì)可以全部訂閱進(jìn)入系統(tǒng)的數(shù)據(jù)話題,或任意訂閱其他團(tuán)隊(duì)對(duì)數(shù)據(jù)進(jìn)行過(guò)某些處理后創(chuàng)建的話題。 這一切并不會(huì)對(duì)數(shù)據(jù)庫(kù)等負(fù)載密集型基礎(chǔ)架構(gòu)造成額外的壓力。 直接寫入Kafka還可避免回壓(Backpressure)問(wèn)題。 回壓是指當(dāng)負(fù)載峰值導(dǎo)致數(shù)據(jù)流入速度超過(guò)組件實(shí)時(shí)處理能力的情況,這種情況可能導(dǎo)致處理工作停頓并可能丟失數(shù)據(jù)。 按照設(shè)計(jì),Kafka可以將數(shù)據(jù)保存很長(zhǎng)時(shí)間,這意味著組件可以在方便的時(shí)候繼續(xù)進(jìn)行處理,并可直接重啟動(dòng)而無(wú)需擔(dān)心造成任何后果。 Samza可以使用以本地鍵值存儲(chǔ)方式實(shí)現(xiàn)的容錯(cuò)檢查點(diǎn)系統(tǒng)存儲(chǔ)數(shù)據(jù)。 這樣Samza即可獲得“至少一次”的交付保障,但面對(duì)由于數(shù)據(jù)可能多次交付造成的失敗,該技術(shù)無(wú)法對(duì)匯總后狀態(tài)(例如計(jì)數(shù))提供精確恢復(fù)。 Samza提供的高級(jí)抽象使其在很多方面比Storm等系統(tǒng)提供的基元(Primitive)更易于配合使用。 目前Samza只支持JVM語(yǔ)言,這意味著它在語(yǔ)言支持方面不如Storm靈活。 總結(jié)對(duì)于已經(jīng)具備或易于實(shí)現(xiàn)Hadoop和Kafka的環(huán)境,Apache Samza是流處理工作負(fù)載一個(gè)很好的選擇。 Samza本身很適合有多個(gè)團(tuán)隊(duì)需要使用(但相互之間并不一定緊密協(xié)調(diào))不同處理階段的多個(gè)數(shù)據(jù)流的組織。 Samza可大幅簡(jiǎn)化很多流處理工作,可實(shí)現(xiàn)低延遲的性能。 如果部署需求與當(dāng)前系統(tǒng)不兼容,也許并不適合使用,但如果需要極低延遲的處理,或?qū)?yán)格的一次處理語(yǔ)義有較高需求,此時(shí)依然適合考慮。 混合處理系統(tǒng):批處理和流處理一些處理框架可同時(shí)處理批處理和流處理工作負(fù)載。 這些框架可以用相同或相關(guān)的組件和API處理兩種類型的數(shù)據(jù),借此讓不同的處理需求得以簡(jiǎn)化。 如你所見(jiàn),這一特性主要是由Spark和Flink實(shí)現(xiàn)的,下文將介紹這兩種框架。 實(shí)現(xiàn)這樣的功能重點(diǎn)在于兩種不同處理模式如何進(jìn)行統(tǒng)一,以及要對(duì)固定和不固定數(shù)據(jù)集之間的關(guān)系進(jìn)行何種假設(shè)。 雖然側(cè)重于某一種處理類型的項(xiàng)目會(huì)更好地滿足具體用例的要求,但混合框架意在提供一種數(shù)據(jù)處理的通用解決方案。 這種框架不僅可以提供處理數(shù)據(jù)所需的方法,而且提供了自己的集成項(xiàng)、庫(kù)、工具,可勝任圖形分析、機(jī)器學(xué)習(xí)、交互式查詢等多種任務(wù)。 Apache SparkApache Spark是一種包含流處理能力的下一代批處理框架。 與Hadoop的MapReduce引擎基于各種相同原則開發(fā)而來(lái)的Spark主要側(cè)重于通過(guò)完善的內(nèi)存計(jì)算和處理優(yōu)化機(jī)制加快批處理工作負(fù)載的運(yùn)行速度。 Spark可作為獨(dú)立集群部署(需要相應(yīng)存儲(chǔ)層的配合),或可與Hadoop集成并取代MapReduce引擎。 批處理模式與MapReduce不同,Spark的數(shù)據(jù)處理工作全部在內(nèi)存中進(jìn)行,只在一開始將數(shù)據(jù)讀入內(nèi)存,以及將最終結(jié)果持久存儲(chǔ)時(shí)需要與存儲(chǔ)層交互。 所有中間態(tài)的處理結(jié)果均存儲(chǔ)在內(nèi)存中。 雖然內(nèi)存中處理方式可大幅改善性能,Spark在處理與磁盤有關(guān)的任務(wù)時(shí)速度也有很大提升,因?yàn)橥ㄟ^(guò)提前對(duì)整個(gè)任務(wù)集進(jìn)行分析可以實(shí)現(xiàn)更完善的整體式優(yōu)化。 為此Spark可創(chuàng)建代表所需執(zhí)行的全部操作,需要操作的數(shù)據(jù),以及操作和數(shù)據(jù)之間關(guān)系的Directed Acyclic Graph(有向無(wú)環(huán)圖),即DAG,借此處理器可以對(duì)任務(wù)進(jìn)行更智能的協(xié)調(diào)。 為了實(shí)現(xiàn)內(nèi)存中批計(jì)算,Spark會(huì)使用一種名為Resilient Distributed Dataset(彈性分布式數(shù)據(jù)集),即RDD的模型來(lái)處理數(shù)據(jù)。 這是一種代表數(shù)據(jù)集,只位于內(nèi)存中,永恒不變的結(jié)構(gòu)。 針對(duì)RDD執(zhí)行的操作可生成新的RDD。 每個(gè)RDD可通過(guò)世系(Lineage)回溯至父級(jí)RDD,并最終回溯至磁盤上的數(shù)據(jù)。 Spark可通過(guò)RDD在無(wú)需將每個(gè)操作的結(jié)果寫回磁盤的前提下實(shí)現(xiàn)容錯(cuò)。 流處理模式流處理能力是由Spark Streaming實(shí)現(xiàn)的。 Spark本身在設(shè)計(jì)上主要面向批處理工作負(fù)載,為了彌補(bǔ)引擎設(shè)計(jì)和流處理工作負(fù)載特征方面的差異,Spark實(shí)現(xiàn)了一種叫做微批(Micro-batch)*的概念。 在具體策略方面該技術(shù)可以將數(shù)據(jù)流視作一系列非常小的“批”,借此即可通過(guò)批處理引擎的原生語(yǔ)義進(jìn)行處理。 Spark Streaming會(huì)以亞秒級(jí)增量對(duì)流進(jìn)行緩沖,隨后這些緩沖會(huì)作為小規(guī)模的固定數(shù)據(jù)集進(jìn)行批處理。 這種方式的實(shí)際效果非常好,但相比真正的流處理框架在性能方面依然存在不足。 優(yōu)勢(shì)和局限使用Spark而非Hadoop MapReduce的主要原因是速度。 在內(nèi)存計(jì)算策略和先進(jìn)的DAG調(diào)度等機(jī)制的幫助下,Spark可以用更快速度處理相同的數(shù)據(jù)集。 Spark的另一個(gè)重要優(yōu)勢(shì)在于多樣性。 該產(chǎn)品可作為獨(dú)立集群部署,或與現(xiàn)有Hadoop集群集成。 該產(chǎn)品可運(yùn)行批處理和流處理,運(yùn)行一個(gè)集群即可處理不同類型的任務(wù)。 除了引擎自身的能力外,圍繞Spark還建立了包含各種庫(kù)的生態(tài)系統(tǒng),可為機(jī)器學(xué)習(xí)、交互式查詢等任務(wù)提供更好的支持。 相比MapReduce,Spark任務(wù)更是“眾所周知”地易于編寫,因此可大幅提高生產(chǎn)力。 為流處理系統(tǒng)采用批處理的方法,需要對(duì)進(jìn)入系統(tǒng)的數(shù)據(jù)進(jìn)行緩沖。 緩沖機(jī)制使得該技術(shù)可以處理非常大量的傳入數(shù)據(jù),提高整體吞吐率,但等待緩沖區(qū)清空也會(huì)導(dǎo)致延遲增高。 這意味著Spark Streaming可能不適合處理對(duì)延遲有較高要求的工作負(fù)載。 由于內(nèi)存通常比磁盤空間更貴,因此相比基于磁盤的系統(tǒng),Spark成本更高。 然而處理速度的提升意味著可以更快速完成任務(wù),在需要按照小時(shí)數(shù)為資源付費(fèi)的環(huán)境中,這一特性通常可以抵消增加的成本。 Spark內(nèi)存計(jì)算這一設(shè)計(jì)的另一個(gè)后果是,如果部署在共享的集群中可能會(huì)遇到資源不足的問(wèn)題。 相比HadoopMapReduce,Spark的資源消耗更大,可能會(huì)對(duì)需要在同一時(shí)間使用集群的其他任務(wù)產(chǎn)生影響。 從本質(zhì)來(lái)看,Spark更不適合與Hadoop堆棧的其他組件共存一處。 總結(jié)Spark是多樣化工作負(fù)載處理任務(wù)的最佳選擇。 Spark批處理能力以更高內(nèi)存占用為代價(jià)提供了無(wú)與倫比的速度優(yōu)勢(shì)。 對(duì)于重視吞吐率而非延遲的工作負(fù)載,則比較適合使用Spark Streaming作為流處理解決方案。 Apache FlinkApache Flink是一種可以處理批處理任務(wù)的流處理框架。 該技術(shù)可將批處理數(shù)據(jù)視作具備有限邊界的數(shù)據(jù)流,借此將批處理任務(wù)作為流處理的子集加以處理。 為所有處理任務(wù)采取流處理為先的方法會(huì)產(chǎn)生一系列有趣的副作用。 這種流處理為先的方法也叫做KAppa架構(gòu),與之相對(duì)的是更加被廣為人知的Lambda架構(gòu)(該架構(gòu)中使用批處理作為主要處理方法,使用流作為補(bǔ)充并提供早期未經(jīng)提煉的結(jié)果)。 Kappa架構(gòu)中會(huì)對(duì)一切進(jìn)行流處理,借此對(duì)模型進(jìn)行簡(jiǎn)化,而這一切是在最近流處理引擎逐漸成熟后才可行的。 流處理模型Flink的流處理模型在處理傳入數(shù)據(jù)時(shí)會(huì)將每一項(xiàng)視作真正的數(shù)據(jù)流。 Flink提供的DataStream API可用于處理無(wú)盡的數(shù)據(jù)流。 Flink可配合使用的基本組件包括:· Stream(流)是指在系統(tǒng)中流轉(zhuǎn)的,永恒不變的無(wú)邊界數(shù)據(jù)集· Operator(操作方)是指針對(duì)數(shù)據(jù)流執(zhí)行操作以產(chǎn)生其他數(shù)據(jù)流的功能· Source(源)是指數(shù)據(jù)流進(jìn)入系統(tǒng)的入口點(diǎn)· Sink(槽)是指數(shù)據(jù)流離開Flink系統(tǒng)后進(jìn)入到的位置,槽可以是數(shù)據(jù)庫(kù)或到其他系統(tǒng)的連接器為了在計(jì)算過(guò)程中遇到問(wèn)題后能夠恢復(fù),流處理任務(wù)會(huì)在預(yù)定時(shí)間點(diǎn)創(chuàng)建快照。 為了實(shí)現(xiàn)狀態(tài)存儲(chǔ),F(xiàn)link可配合多種狀態(tài)后端系統(tǒng)使用,具體取決于所需實(shí)現(xiàn)的復(fù)雜度和持久性級(jí)別。 此外Flink的流處理能力還可以理解“事件時(shí)間”這一概念,這是指事件實(shí)際發(fā)生的時(shí)間,此外該功能還可以處理會(huì)話。 這意味著可以通過(guò)某種有趣的方式確保執(zhí)行順序和分組。 批處理模型Flink的批處理模型在很大程度上僅僅是對(duì)流處理模型的擴(kuò)展。 此時(shí)模型不再?gòu)某掷m(xù)流中讀取數(shù)據(jù),而是從持久存儲(chǔ)中以流的形式讀取有邊界的數(shù)據(jù)集。 Flink會(huì)對(duì)這些處理模型使用完全相同的運(yùn)行時(shí)。 Flink可以對(duì)批處理工作負(fù)載實(shí)現(xiàn)一定的優(yōu)化。 例如由于批處理操作可通過(guò)持久存儲(chǔ)加以支持,F(xiàn)link可以不對(duì)批處理工作負(fù)載創(chuàng)建快照。 數(shù)據(jù)依然可以恢復(fù),但常規(guī)處理操作可以執(zhí)行得更快。 另一個(gè)優(yōu)化是對(duì)批處理任務(wù)進(jìn)行分解,這樣即可在需要的時(shí)候調(diào)用不同階段和組件。 借此Flink可以與集群的其他用戶更好地共存。 對(duì)任務(wù)提前進(jìn)行分析使得Flink可以查看需要執(zhí)行的所有操作、數(shù)據(jù)集的大小,以及下游需要執(zhí)行的操作步驟,借此實(shí)現(xiàn)進(jìn)一步的優(yōu)化。 優(yōu)勢(shì)和局限Flink目前是處理框架領(lǐng)域一個(gè)獨(dú)特的技術(shù)。 雖然Spark也可以執(zhí)行批處理和流處理,但Spark的流處理采取的微批架構(gòu)使其無(wú)法適用于很多用例。 Flink流處理為先的方法可提供低延遲,高吞吐率,近乎逐項(xiàng)處理的能力。 Flink的很多組件是自行管理的。 雖然這種做法較為罕見(jiàn),但出于性能方面的原因,該技術(shù)可自行管理內(nèi)存,無(wú)需依賴原生的Java垃圾回收機(jī)制。 與Spark不同,待處理數(shù)據(jù)的特征發(fā)生變化后Flink無(wú)需手工優(yōu)化和調(diào)整,并且該技術(shù)也可以自行處理數(shù)據(jù)分區(qū)和自動(dòng)緩存等操作。 Flink會(huì)通過(guò)多種方式對(duì)工作進(jìn)行分許進(jìn)而優(yōu)化任務(wù)。 這種分析在部分程度上類似于SQL查詢規(guī)劃器對(duì)關(guān)系型數(shù)據(jù)庫(kù)所做的優(yōu)化,可針對(duì)特定任務(wù)確定最高效的實(shí)現(xiàn)方法。 該技術(shù)還支持多階段并行執(zhí)行,同時(shí)可將受阻任務(wù)的數(shù)據(jù)集合在一起。 對(duì)于迭代式任務(wù),出于性能方面的考慮,F(xiàn)link會(huì)嘗試在存儲(chǔ)數(shù)據(jù)的節(jié)點(diǎn)上執(zhí)行相應(yīng)的計(jì)算任務(wù)。 此外還可進(jìn)行“增量迭代”,或僅對(duì)數(shù)據(jù)中有改動(dòng)的部分進(jìn)行迭代。 在用戶工具方面,F(xiàn)link提供了基于Web的調(diào)度視圖,借此可輕松管理任務(wù)并查看系統(tǒng)狀態(tài)。 用戶也可以查看已提交任務(wù)的優(yōu)化方案,借此了解任務(wù)最終是如何在集群中實(shí)現(xiàn)的。 對(duì)于分析類任務(wù),F(xiàn)link提供了類似SQL的查詢,圖形化處理,以及機(jī)器學(xué)習(xí)庫(kù),此外還支持內(nèi)存計(jì)算。 Flink能很好地與其他組件配合使用。 如果配合Hadoop 堆棧使用,該技術(shù)可以很好地融入整個(gè)環(huán)境,在任何時(shí)候都只占用必要的資源。 該技術(shù)可輕松地與YARN、HDFS和Kafka 集成。 在兼容包的幫助下,F(xiàn)link還可以運(yùn)行為其他處理框架,例如Hadoop和Storm編寫的任務(wù)。 目前Flink最大的局限之一在于這依然是一個(gè)非常“年幼”的項(xiàng)目。 現(xiàn)實(shí)環(huán)境中該項(xiàng)目的大規(guī)模部署尚不如其他處理框架那么常見(jiàn),對(duì)于Flink在縮放能力方面的局限目前也沒(méi)有較為深入的研究。 隨著快速開發(fā)周期的推進(jìn)和兼容包等功能的完善,當(dāng)越來(lái)越多的組織開始嘗試時(shí),可能會(huì)出現(xiàn)越來(lái)越多的Flink部署總結(jié)Flink提供了低延遲流處理,同時(shí)可支持傳統(tǒng)的批處理任務(wù)。 Flink也許最適合有極高流處理需求,并有少量批處理任務(wù)的組織。 該技術(shù)可兼容原生Storm和Hadoop程序,可在YARN管理的集群上運(yùn)行,因此可以很方便地進(jìn)行評(píng)估。 快速進(jìn)展的開發(fā)工作使其值得被大家關(guān)注。 結(jié)論大數(shù)據(jù)系統(tǒng)可使用多種處理技術(shù)。 對(duì)于僅需要批處理的工作負(fù)載,如果對(duì)時(shí)間不敏感,比其他解決方案實(shí)現(xiàn)成本更低的Hadoop將會(huì)是一個(gè)好選擇。 對(duì)于僅需要流處理的工作負(fù)載,Storm可支持更廣泛的語(yǔ)言并實(shí)現(xiàn)極低延遲的處理,但默認(rèn)配置可能產(chǎn)生重復(fù)結(jié)果并且無(wú)法保證順序。 Samza與YARN和Kafka緊密集成可提供更大靈活性,更易用的多團(tuán)隊(duì)使用,以及更簡(jiǎn)單的復(fù)制和狀態(tài)管理。 對(duì)于混合型工作負(fù)載,Spark可提供高速批處理和微批處理模式的流處理。 該技術(shù)的支持更完善,具備各種集成庫(kù)和工具,可實(shí)現(xiàn)靈活的集成。 Flink提供了真正的流處理并具備批處理能力,通過(guò)深度優(yōu)化可運(yùn)行針對(duì)其他平臺(tái)編寫的任務(wù),提供低延遲的處理,但實(shí)際應(yīng)用方面還為時(shí)過(guò)早。 最適合的解決方案主要取決于待處理數(shù)據(jù)的狀態(tài),對(duì)處理所需時(shí)間的需求,以及希望得到的結(jié)果。 具體是使用全功能解決方案或主要側(cè)重于某種項(xiàng)目的解決方案,這個(gè)問(wèn)題需要慎重權(quán)衡。 隨著逐漸成熟并被廣泛接受,在評(píng)估任何新出現(xiàn)的創(chuàng)新型解決方案時(shí)都需要考慮類似的問(wèn)題。
那我就根據(jù)這兩三年的研究與工作經(jīng)歷,說(shuō)說(shuō)如今的情況。
傳統(tǒng)行業(yè),尤其是政府,醫(yī)療,學(xué)校和大企業(yè),基本上還是Oracle應(yīng)用最廣,其次就是DB2。 反而是WebLogic和WebSphere這些中間件基本上隨著經(jīng)典javaee的沒(méi)落,已經(jīng)逐步退出歷史舞臺(tái),被富前端和微服務(wù)框架的輕量級(jí)組合所替代。
傳統(tǒng)行業(yè)的很多新項(xiàng)目也大量開始應(yīng)用MySQL,因?yàn)檩p量級(jí)數(shù)據(jù)庫(kù)的前期成本很低,可以保證項(xiàng)目預(yù)算夠用,所以主要是新項(xiàng)目居多,面向互聯(lián)網(wǎng)連接的項(xiàng)目也居多。 這些系統(tǒng)一般不會(huì)像Oracle一樣承擔(dān)關(guān)鍵性業(yè)務(wù)的數(shù)據(jù)存儲(chǔ),所以選擇什么樣的數(shù)據(jù)庫(kù)都是開發(fā)公司自己的選擇決定。
目前有大量企業(yè)都開始上云,大家買云服務(wù)以阿里云ecs為主,總體上阿里云還是比較穩(wěn)定,那么對(duì)于云上數(shù)據(jù)庫(kù)的穩(wěn)定有要求的企業(yè)一般都會(huì)選擇阿里云主打的的rds系列,MySQL居多,PostgreSQL也開始逐漸被認(rèn)可。
說(shuō)到PostgreSQL,的確這兩年P(guān)G風(fēng)頭正勁,以前我的文章也提到過(guò)我做過(guò)的互聯(lián)網(wǎng)醫(yī)療產(chǎn)品,其架構(gòu)設(shè)計(jì)就選擇采用了PostgreSQL,主要就是看中PostgreSQL在生產(chǎn)上的穩(wěn)定性極高,而且成本很低。 尤其是精通Linux服務(wù)的架構(gòu)師,對(duì)于PostgreSQL更容易掌握。
更具體地說(shuō)就是使用PostgreSQL的關(guān)鍵因素主要還是業(yè)務(wù)數(shù)據(jù)很關(guān)鍵,因?yàn)槲覀儺?dāng)時(shí)承載的是互聯(lián)網(wǎng)醫(yī)療數(shù)據(jù),醫(yī)療數(shù)據(jù)自身屬性就很關(guān)鍵!所以穩(wěn)定和安全都是剛性要求,同時(shí)要平衡成本與互聯(lián)網(wǎng)方式的靈活性,所以才否定了MySQL方案,堅(jiān)決執(zhí)行了PostgreSQL方案。
大數(shù)據(jù)類項(xiàng)目的主數(shù)據(jù)集還是以HadoopHDFS作為基礎(chǔ)存儲(chǔ)設(shè)施。 盡管現(xiàn)在很熱的討論就是Hadoop已經(jīng)是日落黃昏,可以選擇其他更快的NoSQL存儲(chǔ)方案。 實(shí)際上,大數(shù)據(jù)工程師在最終落地的執(zhí)行上,還是很誠(chéng)實(shí)的選擇了Hadoop,因?yàn)槠涑墒於龋€(wěn)定性是最終考量的標(biāo)準(zhǔn)。
ELK家族的Elasticsearch目前被大量作為日志監(jiān)測(cè)分析的主數(shù)據(jù)集去使用,甚至都忽視了它本身是搜索引擎的這個(gè)事實(shí),在電子商務(wù)網(wǎng)站,內(nèi)容發(fā)布網(wǎng)站以及社交媒體網(wǎng)站,Elasticsearch作為專業(yè)搜索引擎,還是穩(wěn)坐第一把交椅。
工業(yè)能源以及其他物聯(lián)網(wǎng)行業(yè),實(shí)時(shí)、時(shí)序數(shù)據(jù)庫(kù)正在逐步采用開源的解決方案,例如、InfluxDB,OpenTSDB,還是目前存儲(chǔ)物聯(lián)網(wǎng)數(shù)據(jù)最好的開源選擇方案。 是實(shí)時(shí)與歷史一整套實(shí)時(shí)庫(kù)解決方案;InfluxDB目前熱度非常高的時(shí)序數(shù)據(jù)庫(kù),自己獨(dú)立實(shí)現(xiàn)了一套原生的集群存儲(chǔ)結(jié)構(gòu);OpenTSDB主要依賴HBase分布式數(shù)據(jù)庫(kù)與HDFS分布式文件系統(tǒng)。 另外提一句,清華推出的開源時(shí)序數(shù)據(jù)庫(kù)IOTDB,目前已經(jīng)升級(jí)成的頂級(jí)項(xiàng)目。
Hadoophbase作為列簇存儲(chǔ),也是毫秒級(jí)的k-v存儲(chǔ),越來(lái)越適應(yīng)通用場(chǎng)景下的實(shí)時(shí)數(shù)據(jù)分析了,可能哪個(gè)領(lǐng)域都有能用到它,支撐實(shí)時(shí)處理的聯(lián)機(jī)分析以及小型批處理業(yè)務(wù)。 它的分布式一致性,存儲(chǔ)hdfs的穩(wěn)定性,都是關(guān)鍵性業(yè)務(wù)數(shù)據(jù)進(jìn)行實(shí)時(shí)分析的極佳方案。
在互聯(lián)網(wǎng)海量數(shù)據(jù)查詢,保證事務(wù)一致性以及大吞吐寫入并行的時(shí)代,就會(huì)形成兩種模式,一種是NewSQL對(duì)關(guān)系型數(shù)據(jù)庫(kù)的替代方案,以前我的文章也不斷提到TiDB對(duì)關(guān)系數(shù)據(jù)庫(kù)替代的必要性,這種替換行為一般會(huì)出現(xiàn)在基于關(guān)系數(shù)據(jù)庫(kù)的上層復(fù)雜業(yè)務(wù)不斷升級(jí)更新帶來(lái)的問(wèn)題,導(dǎo)致運(yùn)維過(guò)程中相關(guān)人員生無(wú)可戀的情況。 那么NewSQL這種分布式一致性,滿足ACID,又帶有k-v水平伸縮存儲(chǔ)的方案就極為合適,不用在關(guān)系數(shù)據(jù)庫(kù)的分庫(kù)分表的泥潭中掙扎。
另一種是關(guān)系數(shù)據(jù)庫(kù)自身的改進(jìn)或者引入MongoDB進(jìn)行部分替代,例如電子商務(wù)的訂單業(yè)務(wù)數(shù)據(jù),互聯(lián)網(wǎng)醫(yī)療的健康檔案數(shù)據(jù),內(nèi)容發(fā)布的文章數(shù)據(jù),都能實(shí)現(xiàn)MongoDB的文檔化替代,這不僅更符合業(yè)務(wù)的文檔化模型,而且能保證事務(wù)的前提下,實(shí)現(xiàn)海量數(shù)據(jù)的支撐。
關(guān)系數(shù)據(jù)庫(kù)也是在不斷改進(jìn)中前進(jìn),尤其是輕量級(jí)數(shù)據(jù)庫(kù)的改進(jìn),MySQL8的cluster特性,PostgreSQL11的并行特性,都是不同手段想要達(dá)到同一個(gè)目的:那就是關(guān)系庫(kù)都在想盡一切辦法,不必讓用戶脫離關(guān)系型數(shù)據(jù)庫(kù),非得擁抱NoSQL才能追求到海量數(shù)據(jù)的并行處理能力,同時(shí)也能降低用戶替換導(dǎo)致的巨大升級(jí)成本。
備注:以上架構(gòu)圖均來(lái)自數(shù)據(jù)庫(kù)官方網(wǎng)站或相關(guān)技術(shù)的權(quán)威網(wǎng)站。
內(nèi)容聲明:
1、本站收錄的內(nèi)容來(lái)源于大數(shù)據(jù)收集,版權(quán)歸原網(wǎng)站所有!
2、本站收錄的內(nèi)容若侵害到您的利益,請(qǐng)聯(lián)系我們進(jìn)行刪除處理!
3、本站不接受違法信息,如您發(fā)現(xiàn)違法內(nèi)容,請(qǐng)聯(lián)系我們進(jìn)行舉報(bào)處理!
4、本文地址:http://m.hudongshop.com/article/3f6464e520acbfe54fd0.html,復(fù)制請(qǐng)保留版權(quán)鏈接!
隨著數(shù)據(jù)密集型應(yīng)用程序的興起,對(duì)高性能存儲(chǔ)解決方案的需求也在不斷增長(zhǎng),PhisonElectronics認(rèn)識(shí)到這一需求,推出了最新的UP10控制器,專為滿足數(shù)據(jù)密集型應(yīng)用程序的嚴(yán)格要求而設(shè)計(jì),Phison,UP10控制器,卓越性能的領(lǐng)航者Phison,UP10控制器采用尖端技術(shù),提供卓越的性能和可靠性,其主要特性包括,支持NVMe1....。
最新資訊 2024-10-01 16:38:35

前言隨著信息技術(shù)的飛速發(fā)展,數(shù)據(jù)已成為驅(qū)動(dòng)企業(yè)發(fā)展的關(guān)鍵資產(chǎn),企業(yè)面臨的挑戰(zhàn)是獲取和處理大量復(fù)雜的數(shù)據(jù),以從中提取有價(jià)值的見(jiàn)解,采集俠應(yīng)運(yùn)而生,它是一個(gè)強(qiáng)大的數(shù)據(jù)采集平臺(tái),旨在幫助企業(yè)應(yīng)對(duì)這些挑戰(zhàn),實(shí)現(xiàn)卓越運(yùn)營(yíng),采集俠簡(jiǎn)介采集俠是一個(gè)基于云端的數(shù)據(jù)采集平臺(tái),旨在簡(jiǎn)化和自動(dòng)化企業(yè)的數(shù)據(jù)采集流程,它提供了一系列工具和功能,讓企業(yè)可以輕松地...。
互聯(lián)網(wǎng)資訊 2024-09-30 20:56:42
簡(jiǎn)介XML,可擴(kuò)展標(biāo)記語(yǔ)言,是一種強(qiáng)大的標(biāo)記語(yǔ)言,用于表示結(jié)構(gòu)化數(shù)據(jù),XSLT,可擴(kuò)展樣式表語(yǔ)言轉(zhuǎn)換,是一種用于轉(zhuǎn)換XML文檔的語(yǔ)言,而XPath,XML路徑語(yǔ)言,是一種用于在XML文檔中選取節(jié)點(diǎn)和值的語(yǔ)言,這兩個(gè)技術(shù)一起使用,可以創(chuàng)建功能強(qiáng)大且靈活的XML數(shù)據(jù)處理解決方案,XSLTXSLT是一種聲明性語(yǔ)言,用于將XML文檔轉(zhuǎn)換為其他...。
技術(shù)教程 2024-09-26 22:49:54

在數(shù)據(jù)集成過(guò)程中,數(shù)據(jù)轉(zhuǎn)換是至關(guān)重要的一個(gè)環(huán)節(jié),它可以幫助我們對(duì)數(shù)據(jù)進(jìn)行格式化、標(biāo)準(zhǔn)化和清洗,從而使其能夠順利地被目標(biāo)系統(tǒng)所接受和處理,在Java中,我們可以使用SpringIntegration框架來(lái)實(shí)現(xiàn)數(shù)據(jù)轉(zhuǎn)換,SpringIntegration提供了一個(gè)名為ResultTransformer的接口,它可以讓我們對(duì)數(shù)據(jù)集成管道中的...。
互聯(lián)網(wǎng)資訊 2024-09-23 20:00:01

在移動(dòng)設(shè)備上提供流暢的滾動(dòng)體驗(yàn)至關(guān)重要,因?yàn)樗梢宰層脩羰孢m地瀏覽內(nèi)容并與應(yīng)用程序交互,在移動(dòng)設(shè)備上優(yōu)化div滾動(dòng)時(shí),需要考慮以下因素,1.避免滾動(dòng)反彈滾動(dòng)反彈是當(dāng)用戶將手指從內(nèi)容頂部或底部拖動(dòng)過(guò)遠(yuǎn)時(shí),內(nèi)容會(huì)反彈回其原始位置的效果,這在移動(dòng)設(shè)備上會(huì)讓人分心,尤其是在小屏幕上,為了避免滾動(dòng)反彈,請(qǐng)使用以下CSS屬性,cssbody,ov...。
互聯(lián)網(wǎng)資訊 2024-09-23 04:27:12

^a%,column,name,>,0,示例3,查找以example結(jié)尾的記錄SELECTFROMtable,nameWHEREPATINDEX,%example$,column,name,>,0,示例4,查找包含數(shù)字123的記錄SELECTFROMtable,nameWHEREPATINDEX,%123%,column,na...。
本站公告 2024-09-14 09:51:21

引言在C,C,編程中,指針是一個(gè)非常重要的概念,它允許程序員直接訪問(wèn)內(nèi)存地址,從而可以高效地處理數(shù)據(jù),指針函數(shù)是C,C,中的一種高級(jí)技術(shù),它將指針與函數(shù)相結(jié)合,可以顯著提升代碼的效率和靈活性,指針函數(shù)的概念指針函數(shù)是一個(gè)指向函數(shù)的指針,換句話說(shuō),它存儲(chǔ)的是函數(shù)的地址,而不是函數(shù)的返回值,與普通函數(shù)不同,指針函數(shù)可以作為參數(shù)傳遞給其...。
技術(shù)教程 2024-09-09 07:10:40

排序是數(shù)據(jù)處理中一項(xiàng)基本任務(wù),在Python中,`sort,`函數(shù)是執(zhí)行此操作的強(qiáng)大工具,本文將提供一個(gè)全面且循序漸進(jìn)的指南,幫助您從新手到大師掌握使用`sort,`函數(shù)排序Python列表,基礎(chǔ)知識(shí)`sort,`函數(shù)的語(yǔ)法```pythonlist.sort,key=None,reverse=False,````key`,可選...。
最新資訊 2024-09-09 00:18:17

概要本文檔提供了一份全面的指南,用于為開發(fā)人員和系統(tǒng)管理員安裝和配置PHP,本指南涵蓋了PHP的高級(jí)安裝配置,包括對(duì)其核心功能的自定義、擴(kuò)展的安裝和配置以及故障排除技巧,目標(biāo)受眾本指南面向有經(jīng)驗(yàn)的開發(fā)人員和系統(tǒng)管理員,他們需要在生產(chǎn)環(huán)境中安裝和配置PHP,讀者應(yīng)具備Linux系統(tǒng)管理和PHP開發(fā)方面的基本知識(shí),前提條件Linux操作系...。
最新資訊 2024-09-07 15:16:26

歡迎來(lái)到Java進(jìn)階的奇妙世界!準(zhǔn)備好踏上探索之旅,解鎖高級(jí)特性并提升您的編程技能了嗎,本文將為您推薦一些寶貴的Java進(jìn)階書籍,為您提供必要的知識(shí)和技能,讓您成為一名出色的Java工程師,1.Java核心技術(shù)卷1,基礎(chǔ)知識(shí)作者,KathySierra,BertBates出版社,人民郵電出版社這本經(jīng)典著作是Java學(xué)習(xí)者的必備書籍,它...。
最新資訊 2024-09-07 13:03:27

在數(shù)學(xué)和編程中,向下取整操作,也稱為舍入,是一種將實(shí)數(shù)四舍五入到其最大整數(shù)的運(yùn)算,地板函數(shù),floor,x,執(zhí)行此操作,向下四舍五入到小于...。
技術(shù)教程 2024-09-05 22:45:20
2019年7月11日,南京市中級(jí)人民法院對(duì)備受社會(huì)關(guān)注的南京碎尸案進(jìn)行公開宣判,被告人朱元璋因故意殺人罪被判處死刑,這起案件給受害者家庭帶來(lái)的傷痛和苦難至今難以愈合,破碎的家庭受害者李某某原本是一個(gè)幸福的三口之家,妻子溫柔賢惠,兒子活潑可愛(ài),碎尸案的發(fā)生,將這個(gè)家庭徹底撕裂,妻子在得知丈夫遇害后,悲痛欲絕,最終因無(wú)法承受打擊而離世,兒...。
互聯(lián)網(wǎng)資訊 2024-09-03 05:35:42