(換膚)
語言:

文章編號:11355時(shí)間:2024-09-30人氣:
在大數(shù)據(jù)時(shí)代,有效處理和分析數(shù)據(jù)變得越來越重要。Plot.log 作為一種強(qiáng)大的工具,為數(shù)據(jù)科學(xué)家和分析師提供了高效處理和分析大數(shù)據(jù)集的方法。
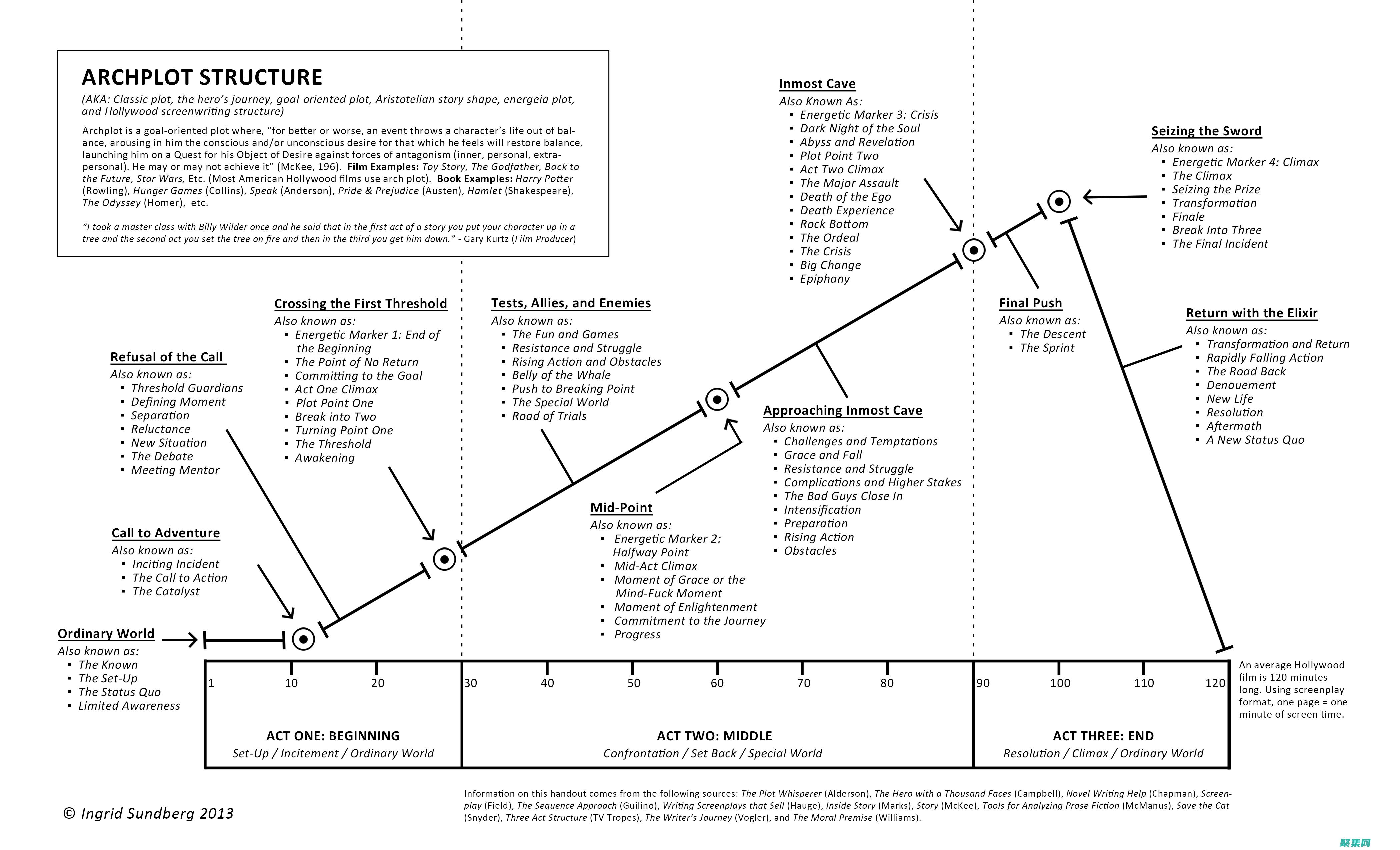
數(shù)據(jù)挖掘的定義 1.技術(shù)上的定義及含義數(shù)據(jù)挖掘(Data Mining)就是從大量的、不完全的、有噪聲的、模糊的、隨機(jī)的實(shí)際應(yīng)用數(shù)據(jù)中,提取隱含在其中的、人們事先不知道的、但又是潛在有用的信息和知識的過程。
這個(gè)定義包括好幾層含義:數(shù)據(jù)源必須是真實(shí)的、大量的、含噪聲的;發(fā)現(xiàn)的是用戶感興趣的知識;發(fā)現(xiàn)的知識要可接受、可理解、可運(yùn)用;并不要求發(fā)現(xiàn)放之四海皆準(zhǔn)的知識,僅支持特定的發(fā)現(xiàn)問題。
與數(shù)據(jù)挖掘相近的同義詞有數(shù)據(jù)融合、人工智能、商務(wù)智能、模式識別、機(jī)器學(xué)習(xí)、知識發(fā)現(xiàn)、數(shù)據(jù)分析和決策支持等。
----何為知識?從廣義上理解,數(shù)據(jù)、信息也是知識的表現(xiàn)形式,但是人們更把概念、規(guī)則、模式、規(guī)律和約束等看作知識。
人們把數(shù)據(jù)看作是形成知識的源泉,好像從礦石中采礦或淘金一樣。
原始數(shù)據(jù)可以是結(jié)構(gòu)化的,如關(guān)系數(shù)據(jù)庫中的數(shù)據(jù);也可以是半結(jié)構(gòu)化的,如文本、圖形和圖像數(shù)據(jù);甚至是分布在網(wǎng)絡(luò)上的異構(gòu)型數(shù)據(jù)。
發(fā)現(xiàn)知識的方法可以是數(shù)學(xué)的,也可以是非數(shù)學(xué)的;可以是演繹的,也可以是歸納的。
發(fā)現(xiàn)的知識可以被用于信息管理,查詢優(yōu)化,決策支持和過程控制等,還可以用于數(shù)據(jù)自身的維護(hù)。
因此,數(shù)據(jù)挖掘是一門交叉學(xué)科,它把人們對數(shù)據(jù)的應(yīng)用從低層次的簡單查詢,提升到從數(shù)據(jù)中挖掘知識,提供決策支持。
在這種需求牽引下,匯聚了不同領(lǐng)域的研究者,尤其是數(shù)據(jù)庫技術(shù)、人工智能技術(shù)、數(shù)理統(tǒng)計(jì)、可視化技術(shù)、并行計(jì)算等方面的學(xué)者和工程技術(shù)人員,投身到數(shù)據(jù)挖掘這一新興的研究領(lǐng)域,形成新的技術(shù)熱點(diǎn)。
這里所說的知識發(fā)現(xiàn),不是要求發(fā)現(xiàn)放之四海而皆準(zhǔn)的真理,也不是要去發(fā)現(xiàn)嶄新的自然科學(xué)定理和純數(shù)學(xué)公式,更不是什么機(jī)器定理證明。
實(shí)際上,所有發(fā)現(xiàn)的知識都是相對的,是有特定前提和約束條件,面向特定領(lǐng)域的,同時(shí)還要能夠易于被用戶理解。
最好能用自然語言表達(dá)所發(fā)現(xiàn)的結(jié)果。
2.商業(yè)角度的定義數(shù)據(jù)挖掘是一種新的商業(yè)信息處理技術(shù),其主要特點(diǎn)是對商業(yè)數(shù)據(jù)庫中的大量業(yè)務(wù)數(shù)據(jù)進(jìn)行抽取、轉(zhuǎn)換、分析和其他模型化處理,從中提取輔助商業(yè)決策的關(guān)鍵性數(shù)據(jù)。
簡而言之,數(shù)據(jù)挖掘其實(shí)是一類深層次的數(shù)據(jù)分析方法。
數(shù)據(jù)分析本身已經(jīng)有很多年的歷史,只不過在過去數(shù)據(jù)收集和分析的目的是用于科學(xué)研究,另外,由于當(dāng)時(shí)計(jì)算能力的限制,對大數(shù)據(jù)量進(jìn)行分析的復(fù)雜數(shù)據(jù)分析方法受到很大限制。
現(xiàn)在,由于各行業(yè)業(yè)務(wù)自動化的實(shí)現(xiàn),商業(yè)領(lǐng)域產(chǎn)生了大量的業(yè)務(wù)數(shù)據(jù),這些數(shù)據(jù)不再是為了分析的目的而收集的,而是由于純機(jī)會的(Opportunistic)商業(yè)運(yùn)作而產(chǎn)生。
分析這些數(shù)據(jù)也不再是單純?yōu)榱搜芯康男枰饕菫樯虡I(yè)決策提供真正有價(jià)值的信息,進(jìn)而獲得利潤。
但所有企業(yè)面臨的一個(gè)共同問題是:企業(yè)數(shù)據(jù)量非常大,而其中真正有價(jià)值的信息卻很少,因此從大量的數(shù)據(jù)中經(jīng)過深層分析,獲得有利于商業(yè)運(yùn)作、提高競爭力的信息,就像從礦石中淘金一樣,數(shù)據(jù)挖掘也因此而得名。
因此,數(shù)據(jù)挖掘可以描述為:按企業(yè)既定業(yè)務(wù)目標(biāo),對大量的企業(yè)數(shù)據(jù)進(jìn)行探索和分析,揭示隱藏的、未知的或驗(yàn)證已知的規(guī)律性,并進(jìn)一步將其模型化的先進(jìn)有效的方法。
數(shù)據(jù)挖掘的功能 數(shù)據(jù)挖掘通過預(yù)測未來趨勢及行為,做出前攝的、基于知識的決策。
數(shù)據(jù)挖掘的目標(biāo)是從數(shù)據(jù)庫中發(fā)現(xiàn)隱含的、有意義的知識,主要有以下五類功能。
1、自動預(yù)測趨勢和行為數(shù)據(jù)挖掘自動在大型數(shù)據(jù)庫中尋找預(yù)測性信息,以往需要進(jìn)行大量手工分析的問題如今可以迅速直接由數(shù)據(jù)本身得出結(jié)論。
一個(gè)典型的例子是市場預(yù)測問題,數(shù)據(jù)挖掘使用過去有關(guān)促銷的數(shù)據(jù)來尋找未來投資中回報(bào)最大的用戶,其它可預(yù)測的問題包括預(yù)報(bào)破產(chǎn)以及認(rèn)定對指定事件最可能作出反應(yīng)的群體。
2、關(guān)聯(lián)分析數(shù)據(jù)關(guān)聯(lián)是數(shù)據(jù)庫中存在的一類重要的可被發(fā)現(xiàn)的知識。
若兩個(gè)或多個(gè)變量的取值之間存在某種規(guī)律性,就稱為關(guān)聯(lián)。
關(guān)聯(lián)可分為簡單關(guān)聯(lián)、時(shí)序關(guān)聯(lián)、因果關(guān)聯(lián)。
關(guān)聯(lián)分析的目的是找出數(shù)據(jù)庫中隱藏的關(guān)聯(lián)網(wǎng)。
有時(shí)并不知道數(shù)據(jù)庫中數(shù)據(jù)的關(guān)聯(lián)函數(shù),即使知道也是不確定的,因此關(guān)聯(lián)分析生成的規(guī)則帶有可信度。
3、聚類數(shù)據(jù)庫中的記錄可被化分為一系列有意義的子集,即聚類。
聚類增強(qiáng)了人們對客觀現(xiàn)實(shí)的認(rèn)識,是概念描述和偏差分析的先決條件。
聚類技術(shù)主要包括傳統(tǒng)的模式識別方法和數(shù)學(xué)分類學(xué)。
80年代初,Mchalski提出了概念聚類技術(shù)牞其要點(diǎn)是,在劃分對象時(shí)不僅考慮對象之間的距離,還要求劃分出的類具有某種內(nèi)涵描述,從而避免了傳統(tǒng)技術(shù)的某些片面性。
4、概念描述概念描述就是對某類對象的內(nèi)涵進(jìn)行描述,并概括這類對象的有關(guān)特征。
概念描述分為特征性描述和區(qū)別性描述,前者描述某類對象的共同特征,后者描述不同類對象之間的區(qū)別。
生成一個(gè)類的特征性描述只涉及該類對象中所有對象的共性。
生成區(qū)別性描述的方法很多,如決策樹方法、遺傳算法等。
5、偏差檢測數(shù)據(jù)庫中的數(shù)據(jù)常有一些異常記錄,從數(shù)據(jù)庫中檢測這些偏差很有意義。
偏差包括很多潛在的知識,如分類中的反常實(shí)例、不滿足規(guī)則的特例、觀測結(jié)果與模型預(yù)測值的偏差、量值隨時(shí)間的變化等。
偏差檢測的基本方法是,尋找觀測結(jié)果與參照值之間有意義的差別。
蒙特卡洛各類常用統(tǒng)計(jì)分布蒙特卡洛模擬數(shù)據(jù)生成的大致思路:1、構(gòu)造自變量x的均勻分布2、根據(jù)對應(yīng)分布的均值函數(shù),構(gòu)造x變量對應(yīng)的均值。
(廣義線性模型的link 函數(shù)參考)3、將均值代入,R中對應(yīng)分布的隨機(jī)變量生成函數(shù),得到因變量y(例如正態(tài)分布為rnorm、泊松分布為rpois)#生成多元正態(tài)數(shù)據(jù),使用MASS 包中的mvrnorm()函數(shù),其格式為mvrnorm(n, mean, sigma),其中n 是你想要的樣本大小,mean 為均值向量,而sigma 是方差—協(xié)方差矩陣(或相關(guān)矩陣)library(MASS, =C:/Program Files/Microsoft/R Open/R-3.4.0/library)?mvrnormn=100alpha=c()for(i in 1:1000){mu1=c(0,0)sigma1=matrix(c(1,0.5,0.5,1.25),nrow=2)rand1=mvrnorm(n=100,mu=mu1,Sigma=sigma1)X=rand1[,1]Y=rand1[,2]alpha[i]=(var(Y)-cov(X,Y))/(var(X)+var(Y)-2*cov(X,Y))#cov函數(shù)計(jì)算的是列與列的協(xié)方差#協(xié)方差是統(tǒng)計(jì)學(xué)上表示兩個(gè)隨機(jī)變量之間的相關(guān)性,隨機(jī)變量ξ的離差與隨機(jī)變量η的離差的乘積的數(shù)學(xué)期望叫做隨機(jī)變量ξ與η的協(xié)方差(也叫相關(guān)矩),記作cov(ξ, η):}alphamean(alpha)var(alpha)sqrt(var(alpha))8.自助法自助法(Bootstrap Method,Bootstrapping或自助抽樣法)是一種從給定訓(xùn)練集中有放回的均勻抽樣,也就是說,每當(dāng)選中一個(gè)樣本,它等可能地被再次選中并被再次添加到訓(xùn)練集中。
自助法,即從初始樣本重復(fù)隨機(jī)替換抽樣,生成一個(gè)或一系列待檢驗(yàn)統(tǒng)計(jì)量的經(jīng)驗(yàn)分布,無需假設(shè)一個(gè)特定的理論分布,便可生成統(tǒng)計(jì)量的置信敬意,并能檢驗(yàn)統(tǒng)計(jì)假設(shè)。
倘若假設(shè)均值的樣本分布不是正態(tài)分布,可使用自助法:(1)從樣本中隨機(jī)選擇10個(gè)觀測,抽樣后再放回。
有些觀測可能會被選擇多次,有些可能一直都不會被選中;(2)計(jì)算并記錄樣本均值;(3)重復(fù)1和2一千次;(4)將1000個(gè)樣本均值從小到大排序;(5)找出樣本均值2.5%和97.5%的分位點(diǎn),此時(shí)即初始位置和最末位置的第25個(gè)數(shù),它們就限定了95%的置信區(qū)間。
樣本均值很可能服從正態(tài)分布,自助法優(yōu)勢不太明顯;但若不服從正態(tài)分布,自助法優(yōu)勢 十分明顯。
{label=c(1:100)rand=cbind(rand1,label)lab=sample(c(1:100),1,replace=TRUE)ran=rand1[label==lab,]for(j in 1:99){lab=sample(c(1:100),1,replace=TRUE)ran2=rand1[label==lab,]ran=rbind(ran,ran2)}X=ran[,1]Y=ran[,2]alpha[j]=(var(Y)-cov(X,Y))/(var(X)+var(Y)-2*cov(X,Y))}rand1[sample(c(1:100),100,replace=TRUE),]523d= (,Header=TRUE)dc= d[(d),]#處理缺失值/空值hist(d$y)d0=d[d$y==0,]d1=d[d$y==1,]d2=d[d$y==2,]d3=d[d$y==3,]label0=sample(c(1:10),dim(d0[1]),replace=TRUE)label1=sample(c(1:10),dim(d1[1]),replace=TRUE)label2=sample(c(1:10),dim(d2[1]),replace=TRUE)label3=sample(c(1:10),dim(d3[1]),replace=TRUE)d0_train=d0[label0<=5,]d0_test=d0[label0>5,]d1_train=d1[label1<=5,]d1_test=d1[label1>5,]d2_train=d2[label2<=5,]d2_test=d2[label2>5,]d3_train=d3[label3<=5,]d3_test=d3[label3>5,]d_train=rbind(d0_train,d1_train,d2_train,d3_train)d_test=rbind(d0_test,d1_test,d2_test,d3_test)邏輯回歸library(nnet)re_log=multinom(y~.-id,data=d_train)pred_log=predict(re_log,newdata=d_test)summary(pred_log)tab_log=table(d_test$y,pred_log)tab_logID3library(rpart)re_id3=rpart(y~.-id,data=d_train,method=class,parms=list(split=information))re_CART=rpart(y~.-id,data=d_train,method=class,parms=list(split=gini),control=(cp=0.0001))min=(re_CART$cptable[,4])剪枝re_CART_f=prune(re_CART,cp=re_CART$cptable[min,1])pred_id3=predict(re_id3,newdata=d_test,type=class)pred_id3table(d_test$y,pred_id3)pred_CART=predict(re_CART_f,newdata=d_test,type=class)table(d_test$y,pred_CART)plot(re_CART)text(re_CART)看不同cp 的分類情況re_id3$cptablere_CART$cptable隨機(jī)森林d_train$y=(d_train$y)re_rf=randomForest(y~.-id,data=d_train,ntree=5)為了畫ROA 曲線資產(chǎn)收益率把所有不等于0的都當(dāng)成是1先重新運(yùn)行d_test(d0= d$y..d_test rbind)d_train$y[d_train$y>=1]=1d_test$y[d_test$y>=1]=1re_rf=randomForest(y~.-id,data=d_train,ntree=5)pred_rf=predict(re_rf,newdata=d_test,type=prob)pred <- prediction(pred_rf[,2],d_test$y)perf <- performance(pred,tpr,fpr)plot(perf,colorize=TRUE)84d = (,header=TRUE)dc = d[,2:9]#標(biāo)準(zhǔn)化sdc = scale(dc)mean(sdc[,1])#求協(xié)方差矩陣cov_sdc=cov(sdc)#求特征值以及其對應(yīng)的特征向量eigen(cov_sdc)#做主成分分析princomp(dc)prcomp(dc)prcomp(sdc)d = (,=)# 定義&標(biāo)記哪些是空值View(d)dc = d[(d),]dim(d)dim(dc)#計(jì)算馬氏距離清楚異常值mdist = function(x){t = (x)m = apply(t,2,mean)s = var(t) return(mahalanobis(t,m,s)) }dc1 = dc[dc$BAD==1,]dc0 = dc[dc$BAD==0,]mdc1 = mdist(dc1[,-c(1,5,6)])mdc0 = mdist(dc0[,-c(1,5,6)])dim(dc1)dim(dc0)summary(mdc1)summary(mdc0)#卡方分布qchisq(p ,df 自由度)#馬氏距離和卡方分布的值做比較,取小于卡方分布的c = qchisq(0.99,10)x1 = dc1[mdc1
你的cad版本我估計(jì)較低,有可能是autocad2004以下的版本。 在選項(xiàng)對話框中高級一點(diǎn)的版本都會有“打印和發(fā)布”面板,在該面板中,你把那個(gè)“自動保存打印并發(fā)布日志”勾選框打的勾去掉,即可達(dá)到你要求。 參見附圖
1、啟動matlab,主界面如圖所示,單擊New Script。
2、在彈出編輯器中輸入代碼,如下所示。
3、單擊“保存”并將其命名為zitu。 當(dāng)然,您也可以將其命名為您想要的名字。
4、保存文件的位置應(yīng)該與搜索路徑相同。 通過右鍵單擊窗口中的文件和彈出的下拉框,可以輕松完成此操作。
5、最后在命令行窗口中輸入zitu。 可以看出,在同一圖片中出現(xiàn)了四個(gè)子圖,每張圖片的顏色和線型不同。 這是在plot命令中實(shí)現(xiàn)的。
內(nèi)容聲明:
1、本站收錄的內(nèi)容來源于大數(shù)據(jù)收集,版權(quán)歸原網(wǎng)站所有!
2、本站收錄的內(nèi)容若侵害到您的利益,請聯(lián)系我們進(jìn)行刪除處理!
3、本站不接受違法信息,如您發(fā)現(xiàn)違法內(nèi)容,請聯(lián)系我們進(jìn)行舉報(bào)處理!
4、本文地址:http://m.hudongshop.com/article/1e358092c2666735b036.html,復(fù)制請保留版權(quán)鏈接!

單擊,高級選項(xiàng),以訪問高級系統(tǒng)設(shè)置,設(shè)置系統(tǒng)還原本地備份,此設(shè)置允許您將系統(tǒng)還原到早期時(shí)間點(diǎn),它與Windows備份不同,Windows備份允許您備份文件和文件夾,系統(tǒng)保護(hù),此設(shè)置允許您啟用或禁用系統(tǒng)還原,啟動和故障恢復(fù),此設(shè)置允許您配置啟動和故障恢復(fù)選項(xiàng),遠(yuǎn)程桌面,此設(shè)置允許您啟用或禁用遠(yuǎn)程桌面功能,系統(tǒng)屬性,此設(shè)置允許您查看系統(tǒng)屬...。
最新資訊 2024-10-01 09:24:15
前言在數(shù)據(jù)處理任務(wù)中,排序是必不可少的一步,它涉及按特定條件將數(shù)據(jù)元素按順序排列,傳統(tǒng)的Linux系統(tǒng)提供了一些基本的排序工具,例如`sort`,但它們的功能有限,無法滿足復(fù)雜或大規(guī)模數(shù)據(jù)集的排序需求,為了填補(bǔ)這一空白,LinuxSort應(yīng)運(yùn)而生,這是一款為Linux系統(tǒng)量身定制的高級數(shù)據(jù)排序?qū)嵱贸绦颍峁V泛的功能和優(yōu)化,以處理復(fù)雜...。
技術(shù)教程 2024-09-30 20:02:59

如果你是一個(gè)想要開發(fā)安卓游戲的初學(xué)者,那么你已經(jīng)到了正確的地方,本指南將帶你完成安卓游戲開發(fā)的各個(gè)階段,從入門到發(fā)布你的游戲,先決條件一部運(yùn)行Android4.1或更高版本的Android設(shè)備一個(gè)文本編輯器,如記事本,、Atom或VisualStudioCode,AndroidStudioJava編程語言的基礎(chǔ)知識設(shè)置環(huán)境1.下載并...。
互聯(lián)網(wǎng)資訊 2024-09-29 08:09:59
前言在當(dāng)今數(shù)據(jù)驅(qū)動的世界中,Excel已成為組織和管理數(shù)據(jù)最常用的工具之一,為了有效地使用Excel,擁有正確的數(shù)據(jù)管理和組織技能至關(guān)重要,本指南將向您展示如何創(chuàng)建整潔高效的工作表,最大限度地提高您的工作效率和準(zhǔn)確性,數(shù)據(jù)輸入數(shù)據(jù)輸入是數(shù)據(jù)管理過程中的第一步,以下是一些最佳實(shí)踐,使用一致的格式,對于數(shù)字、日期和文本字段,使用相同的小數(shù)...。
最新資訊 2024-09-29 03:05:30

在當(dāng)今數(shù)字化的時(shí)代,企業(yè)網(wǎng)站是企業(yè)在線業(yè)務(wù)的關(guān)鍵組成部分,一個(gè)高績效的網(wǎng)站可以有效地吸引流量、轉(zhuǎn)化潛在客戶并推動業(yè)務(wù)增長,構(gòu)建一個(gè)這樣的網(wǎng)站需要精心策劃和執(zhí)行一系列經(jīng)過驗(yàn)證的策略,1.優(yōu)化搜索引擎,SEO,SEO通過提高網(wǎng)站在搜索引擎結(jié)果頁面,SERP,中的排名來提高有機(jī)流量,實(shí)施以下策略以優(yōu)化SEO,關(guān)鍵字研究,確定與您的業(yè)務(wù)和目標(biāo)...。
本站公告 2024-09-27 03:27:56

四舍五入是開發(fā)中一個(gè)常見的操作,在PHP中有幾種方法可以處理四舍五入,本文將探討最優(yōu)雅和高效的方法,round,函數(shù)round,函數(shù)是四舍五入的基本函數(shù),它采用兩個(gè)參數(shù),要四舍五入的數(shù)字和保留的小數(shù)位數(shù),可選,如果省略小數(shù)位數(shù),則數(shù)字將四舍五入到最接近的整數(shù),floor,和ceil,函數(shù)floor,和ceil,函數(shù)用于分...。
本站公告 2024-09-23 11:13:27

數(shù)據(jù)庫編程的主要內(nèi)容數(shù)據(jù)庫編程是計(jì)算機(jī)編程的一個(gè)分支,專門與數(shù)據(jù)庫的存儲、檢索和管理有關(guān),數(shù)據(jù)庫是存儲和組織大量數(shù)據(jù)的電子系統(tǒng),而數(shù)據(jù)庫編程則涉及編寫和執(zhí)行計(jì)算機(jī)指令來與數(shù)據(jù)庫交互,數(shù)據(jù)庫編程涉及以下主要方面,數(shù)據(jù)建模,設(shè)計(jì)和創(chuàng)建數(shù)據(jù)庫結(jié)構(gòu),定義表、字段和關(guān)系,數(shù)據(jù)操作,使用SQL,結(jié)構(gòu)化查詢語言,查詢、插入、更新和刪除數(shù)據(jù)庫中的數(shù)據(jù)...。
最新資訊 2024-09-10 12:12:31

在JavaScript中,獲取當(dāng)前月份非常簡單,我們只需要創(chuàng)建一個(gè)新的Date對象,然后調(diào)用該對象的getMonth,方法即可,getMonth,方法返回一個(gè)介于0到11之間的整數(shù),其中0表示1月,11表示12月,以下是如何在JavaScript中獲取當(dāng)前月份的示例代碼,```javascriptconsttoday=newDat...。
最新資訊 2024-09-10 08:52:55

前言Java是一種面向?qū)ο缶幊陶Z言,以其平臺無關(guān)性和安全性而聞名,它是世界上最流行的編程語言之一,用于開發(fā)各種應(yīng)用程序,從桌面軟件到移動應(yīng)用程序,再到Web服務(wù),如果你正在尋找一本關(guān)于Java核心技術(shù)的全面教程,那么馬士兵的,Java教程實(shí)戰(zhàn)詳解,是一個(gè)不錯的選擇,這本教程由資深Java開發(fā)人員撰寫,內(nèi)容豐富且深入淺出,非常適合初學(xué)者...。
技術(shù)教程 2024-09-09 21:27:48

簡介NORM函數(shù)是MATLAB中一個(gè)多功能的數(shù)據(jù)處理工具,可用于計(jì)算數(shù)組或標(biāo)量的絕對值,它比直接使用ABS函數(shù)更通用,因?yàn)镹ORM函數(shù)還可以指定符號,用法NORM函數(shù)的語法如下,norm,X,norm,X,P,norm,X,P,DIM,其中,X是要計(jì)算范數(shù)的數(shù)組或標(biāo)量,P指定范數(shù)類型,P的有效值包括,1,計(jì)算1范數(shù),即數(shù)組中元素的絕對...。
本站公告 2024-09-09 19:20:43

引言Java是一種面向?qū)ο蟮木幊陶Z言,以其跨平臺、高效和易用的特點(diǎn)而聞名,它廣泛應(yīng)用于從企業(yè)應(yīng)用程序到移動應(yīng)用程序的各種領(lǐng)域,作為一名Java開發(fā)人員,掌握核心概念、最佳實(shí)踐和高級技巧至關(guān)重要,教程將為您提供全面指南,幫助您提升您的Java技能,核心概念面向?qū)ο缶幊蹋琌OP,Java是一種面向?qū)ο蟮恼Z言,這意味著它圍繞對象的概念組織...。
最新資訊 2024-09-07 13:01:25

引言在實(shí)際開發(fā)中,我們經(jīng)常需要使用隨機(jī)數(shù)來解決各種問題,例如生成驗(yàn)證碼、抽獎、模擬數(shù)據(jù)等,并不是所有的隨機(jī)數(shù)都是真正的隨機(jī)數(shù),有些隨機(jī)數(shù)可能是偽隨機(jī)數(shù),甚至是可預(yù)測的,因此,選擇合適的隨機(jī)數(shù)生成方法非常重要,本文將全面介紹PHP中生成真正的隨機(jī)數(shù)的方法,并提供詳細(xì)的代碼示例,什么是真正的隨機(jī)數(shù),真正的隨機(jī)數(shù)是指無法通過任何算法或公式預(yù)...。
互聯(lián)網(wǎng)資訊 2024-09-05 21:34:09